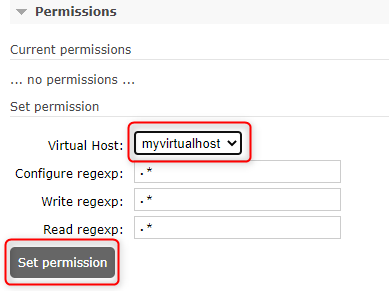
Rebuilding a Partitioned Index
I regularly work with some very large tables that use SQL Server Partitions. We use daily, weekly, or monthly partitions based on the frequency of the data we are receiving. Just to give you an idea of what I am dealing with, I have one table that uses daily partitions and has 500 Billion rows!
The main issue I run into is dealing with index fragmentation. Once I am done inserting data into a partition of historical data, I want to defragment the index on that partition since I don’t have to worry about it fragmenting again. In SQL Server 2012 and older the problem was that when I wanted to rebuild partitions ONLINE I had to rebuild ALL partitions on the table, or do it OFFLINE if rebuilding a single partition. Neither of these options were ideal.
The good news is that as of SQL Server 2014 we now have the ability to rebuild a single partition ONLINE, for example:
ALTER INDEX PK_MY_INDEX
ON Tutorial.MY_TABLE
REBUILD PARTITION = 123
WITH (ONLINE = ON)
For my partitions that are time based, once the time period has passed, only that partition needs to have it’s index rebuilt. In this use case it is a big advantage to be able to rebuild the index on a single partition or a range of partitions as part of regularly scheduled maintenance.
As an example, let’s create a table with a partitioned index, add some data, and cause the index to become fragmented. In this example I will show you some of the common scripts I use to detect fragmentation and rebuild a range of indexes online.
Create a Table with a Partitioned Index
Lets start by creating a partition table and index.
Create a partition function by month for a year.
CREATE partition FUNCTION MonthlyPartitionFunction (smalldatetime) AS range RIGHT FOR VALUES (
N'2023-02-01T00:00:00',
N'2023-03-01T00:00:00',
N'2023-04-01T00:00:00',
N'2023-05-01T00:00:00',
N'2023-06-01T00:00:00',
N'2023-07-01T00:00:00',
N'2023-08-01T00:00:00',
N'2023-09-01T00:00:00',
N'2023-10-01T00:00:00',
N'2023-11-01T00:00:00',
N'2023-12-01T00:00:00',
N'2024-01-01T00:00:00');
GO
Note: The dates above are the end date of the partition. So if you insert a record with the datetime 2023-03-22 it will be in partition 2023-04-01. If you want to get a better understanding of range LEFT vs range RIGHT, you can get a good explanation here.
Create a partition scheme using our monthly partition. The partition scheme maps the partition function to a filegroup which maps to the physical files stored on disk.
CREATE PARTITION SCHEME MonthlyPartitionScheme
AS PARTITION MonthlyPartitionFunction ALL TO ([PRIMARY])
GO
Create a table to store our timeseries history data.
CREATE TABLE dbo.TimeSeriesHistory(
[TimeSeriesID] int NOT NULL,
[RecordDateTime] smalldatetime NOT NULL,
[Value] real NOT NULL)
GO
Finally let’s create a primary key index on our table using our monthly partition scheme.
ALTER TABLE dbo.TimeSeriesHistory
ADD CONSTRAINT PK_TimeSeriesHistory_TimeSeriesID_RecordDateTime
PRIMARY KEY CLUSTERED (
TimeSeriesID ASC,
RecordDateTime ASC
)
WITH (
IGNORE_DUP_KEY = ON,
ONLINE = ON,
PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON
)
ON MonthlyPartitionScheme(RecordDateTime);
GO
Generate Test Data
Now let’s insert some data into our new table and since we are not inserting the data in order, we should end up with fragmented indexes on each partition.
DECLARE @current int = 1;
DECLARE @end int = 100000;
WHILE @current < @end
BEGIN
DECLARE @date smalldatetime = DATEADD(DAY, ABS(CHECKSUM(NEWID()) % 364 ), '2023-01-01')
DECLARE @a varchar(32)
SET @a = convert(varchar(32), @date, 121)
RAISERROR('Insert data for %s', 0, 1, @a) WITH NOWAIT
INSERT INTO dbo.TimeSeriesHistory (TimeSeriesID, RecordDateTime, [Value])
VALUES (FLOOR(RAND()*(10000)+1), @date, ROUND(RAND() *100000, 0))
SET @current = @current + 1;
END
GO
This query shows the test data that was generated, rolled up by month.
SELECT
DATEPART(YEAR, RecordDateTime) AS year,
DATEPART(MONTH, RecordDateTime) AS month,
COUNT(TimeSeriesID) AS count
FROM dbo.TimeSeriesHistory
GROUP BY
DATEPART(YEAR, RecordDateTime),
DATEPART(MONTH, RecordDateTime)
ORDER BY
DATEPART(YEAR, RecordDateTime),
DATEPART(MONTH, RecordDateTime);
year month count
----------- ----------- -----------
2023 1 8315
2023 2 7648
2023 3 8355
2023 4 8085
2023 5 8428
2023 6 8174
2023 7 8420
2023 8 8396
2023 9 8075
2023 10 8436
2023 11 8213
2023 12 8111This next query shows the total number of rows per partition.
SELECT partition_number AS 'PartitionNumber',
prv.value AS 'PartitionName',
[rows] AS 'TotalRows'
FROM sys.partitions p
INNER JOIN sys.objects o
ON p.object_id = o.object_id
INNER JOIN sys.indexes i
ON p.object_id = i.object_id
AND p.index_id = i.index_id
INNER JOIN sys.partition_schemes ps
ON ps.data_space_id = i.data_space_id
LEFT OUTER JOIN sys.partition_range_values prv
ON ps.function_id = prv.function_id
AND p.partition_number = prv.boundary_id
WHERE i.name = 'PK_TimeSeriesHistory_TimeSeriesID_RecordDateTime'
ORDER BY partition_number
PartitionNumber PartitionName TotalRows
--------------- -------------------------- --------------------
1 2023-02-01 00:00:00.000 8315
2 2023-03-01 00:00:00.000 7648
3 2023-04-01 00:00:00.000 8355
4 2023-05-01 00:00:00.000 8085
5 2023-06-01 00:00:00.000 8428
6 2023-07-01 00:00:00.000 8174
7 2023-08-01 00:00:00.000 8420
8 2023-09-01 00:00:00.000 8396
9 2023-10-01 00:00:00.000 8075
10 2023-11-01 00:00:00.000 8436
11 2023-12-01 00:00:00.000 8213
12 2024-01-01 00:00:00.000 8111Now that we have our partitioned table populated with data, we can look at how to check index fragmentation and rebuild the indexes.
Check Index Fragmentation
We can check the fragmentation percentage of the index on each partition by providing the name of the index to the following query.
SELECT
a.partition_number AS 'PartitionNumber',
prv.value AS 'PartitionName',
a.avg_fragmentation_in_percent AS 'FragmentationPercentage'
FROM sys.indexes i
INNER JOIN sys.partition_schemes ps
ON ps.data_space_id = i.data_space_id
JOIN sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL , NULL, 'LIMITED') a
ON a.object_id = i.object_id and a.index_id = i.index_id
LEFT OUTER JOIN sys.partition_range_values prv
ON ps.function_id = prv.function_id
AND a.partition_number = prv.boundary_id
WHERE i.name = 'PK_TimeSeriesHistory_TimeSeriesID_RecordDateTime'
You can see in the output below that the indexes on each partition have fragmentation.
PartitionNumber PartitionName FragmentationPercentage
--------------- -------------------------- -----------------------
1 2023-02-01 00:00:00.000 96.875
2 2023-03-01 00:00:00.000 96.875
3 2023-04-01 00:00:00.000 96.875
4 2023-05-01 00:00:00.000 96.774
5 2023-06-01 00:00:00.000 96.875
6 2023-07-01 00:00:00.000 96.875
7 2023-08-01 00:00:00.000 96.875
8 2023-09-01 00:00:00.000 96.875
9 2023-10-01 00:00:00.000 96.875
10 2023-11-01 00:00:00.000 96.875
11 2023-12-01 00:00:00.000 96.875
12 2024-01-01 00:00:00.000 96.875Rebuild Indexes For a Range of Partitions
When I have a range of partitions where the indexes are fragmented, I find the simplest way to rebuild all the indexes is to just loop through the partition IDs and rebuild each partition index, one at a time, online. For our example table we can loop through the partition IDs 1 to 12.
DECLARE
@CurrentPartitionNumber int = 1
, @EndPartitionNumber int = 12;
WHILE @CurrentPartitionNumber <= @EndPartitionNumber
BEGIN
RAISERROR('Rebuilding partition %d', 0, 1, @CurrentPartitionNumber) WITH NOWAIT;
ALTER INDEX PK_TimeSeriesHistory_TimeSeriesID_RecordDateTime
ON dbo.TimeSeriesHistory
REBUILD Partition = @CurrentPartitionNumber
WITH(ONLINE=ON);
SET @CurrentPartitionNumber += 1;
END;
GO
Here is the output from running the script.
Rebuilding partition 1
Rebuilding partition 2
Rebuilding partition 3
Rebuilding partition 4
Rebuilding partition 5
Rebuilding partition 6
Rebuilding partition 7
Rebuilding partition 8
Rebuilding partition 9
Rebuilding partition 10
Rebuilding partition 11
Rebuilding partition 12If you run the script to check index fragmentation again, you will see that the fragmentation percentage has improved.
PartitionNumber PartitionName FragmentationPercentage
--------------- -------------------------- -----------------------
1 2023-02-01 00:00:00.000 4.545
2 2023-03-01 00:00:00.000 5
3 2023-04-01 00:00:00.000 4.545
4 2023-05-01 00:00:00.000 4.762
5 2023-06-01 00:00:00.000 4.545
6 2023-07-01 00:00:00.000 4.545
7 2023-08-01 00:00:00.000 4.545
8 2023-09-01 00:00:00.000 4.545
9 2023-10-01 00:00:00.000 4.762
10 2023-11-01 00:00:00.000 4.545
11 2023-12-01 00:00:00.000 4.545
12 2024-01-01 00:00:00.000 4.545Scheduled Maintenance
To avoid having to perform manual maintenance on the indexes on partitioned tables, the simplest option is to just create a scheduled SQL Agent Job and have this done for you automatically.
For this example where we have a table with monthly partitions, we could create a SQL Agent job to run on the first of each month and rebuild the previous months partition.
If we run the following script on Dec 1st, 2023, it will rebuild the index for the most recent partition to which we are no longer adding any more data, which is 2023-12-01, partition number 11.
Here is the script.
DECLARE @CurrentPartitionNumber int = 0;
DECLARE @EndPartitionNumber int = 0;
-- Get the min and max partition numbers to rebuild
SELECT @CurrentPartitionNumber = MIN(a.partition_number),
@EndPartitionNumber = MAX(a.partition_number)
FROM sys.partitions a
JOIN sys.indexes i on a.object_id = i.object_id and a.index_id = i.index_id
INNER JOIN sys.partition_schemes ps
ON ps.data_space_id = i.data_space_id
LEFT OUTER JOIN sys.partition_range_values prv
ON ps.function_id = prv.function_id AND a.partition_number = prv.boundary_id
WHERE i.name = 'PK_TimeSeriesHistory_TimeSeriesID_RecordDateTime'
AND year(CAST(prv.[value] AS smalldatetime)) = year(GETUTCDATE())
AND month(CAST(prv.[value] AS smalldatetime)) = month(GETUTCDATE())
-- Rebuild the partitions one at a time
WHILE @CurrentPartitionNumber <= @EndPartitionNumber
BEGIN
RAISERROR('Rebuilding partition %d', 0, 1, @CurrentPartitionNumber) WITH NOWAIT;
ALTER INDEX PK_TimeSeriesHistory_TimeSeriesID_RecordDateTime
ON dbo.TimeSeriesHistory
REBUILD Partition = @CurrentPartitionNumber
WITH(ONLINE=ON);
SET @CurrentPartitionNumber += 1;
END;
GO
In the output, you can see that the script only rebuilt the index for partition 11.
Rebuilding partition 11
Completion time: 2023-12-01T16:23:11.9621045-06:00You can easily adjust the WHERE clause of this script to rebuild a longer range of partitions for whatever you need for your use case (e.g., weekly job to rebuild the daily partitions for the last seven days).
Summary
Partitioning tables in SQL Server is a very useful tool to manage large amounts of data. Now that we can rebuild indexes per partition online it gives us a lot more flexibility to maintain a large table where downtime is not an option.
I hope this helps!